Multi-label Triplet Embeddings for Image Annotation from User-Generated Tags
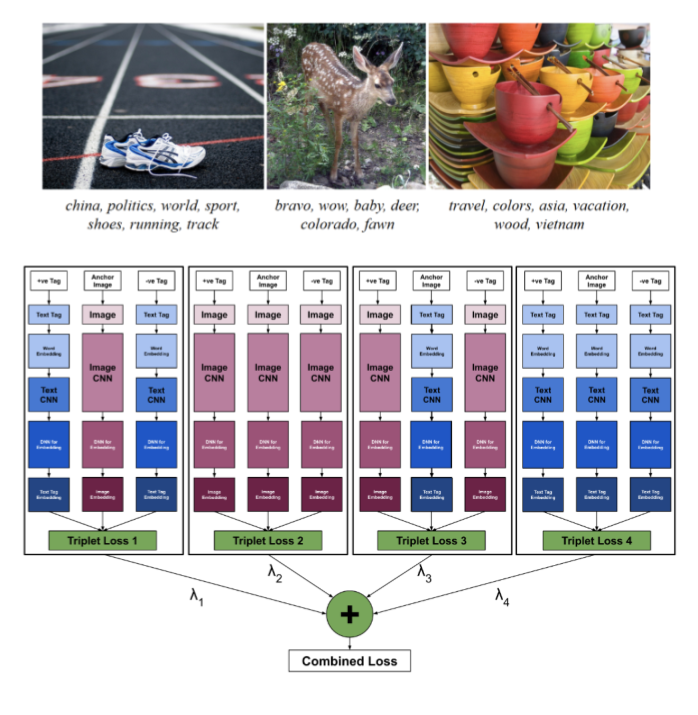 (Above) Labels for images samples. Labels include example of semantically simple and complex labels.
(Below) Proposed architecture for choosing combination of various possible triplet loss
(Above) Labels for images samples. Labels include example of semantically simple and complex labels.
(Below) Proposed architecture for choosing combination of various possible triplet loss
To predict (extract) semantic labels for a given image. This is achieved by using triplet loss on latent embedding (features) for images and text-labels.
Raunak Sinha
Staff Research Engineer, Artificial Intelligence
I am interested in developing learning theory for computational sustainability, computer vision and natural language understanding.